Empower: Save up to 80% on LLM bills with 5 lines of code changes
Meet Empower AFT, the Auto Fine-Tuning platform for small language models.
Problem: Fine-tuning SLMs to replace the general-purpose LLM is hard
Despite recent pricing drops, general-purpose large language models like GPT4 and Sonnet remain costly for many use cases. With rates at around $5 per million tokens on average, even simple tasks can exceed $0.10 on the cost, significantly limiting their use in many scenarios.
Fine-tuned small language models (SLMs), such as llama3 8B, can achieve performance on par with, or even surpass, general-purpose LLMs in task-specific scenarios. However, the process of fine-tuning an SLM requires significant engineering effort. Tasks such as data collection, model iteration and evaluation, and deployment management are time-consuming for engineering teams.
Solution
Empower’s Auto Fine-Tuning (AFT) platform offers a one-stop solution for model fine-tuning. With AFT, users need to modify just five lines of code, while the platform handles everything else, including data collection, SLM training, evaluation, hosting, and traffic management. Additionally, AFT offers automatic model retraining to ensure consistent fine-tuned model performance over time.
How It Works
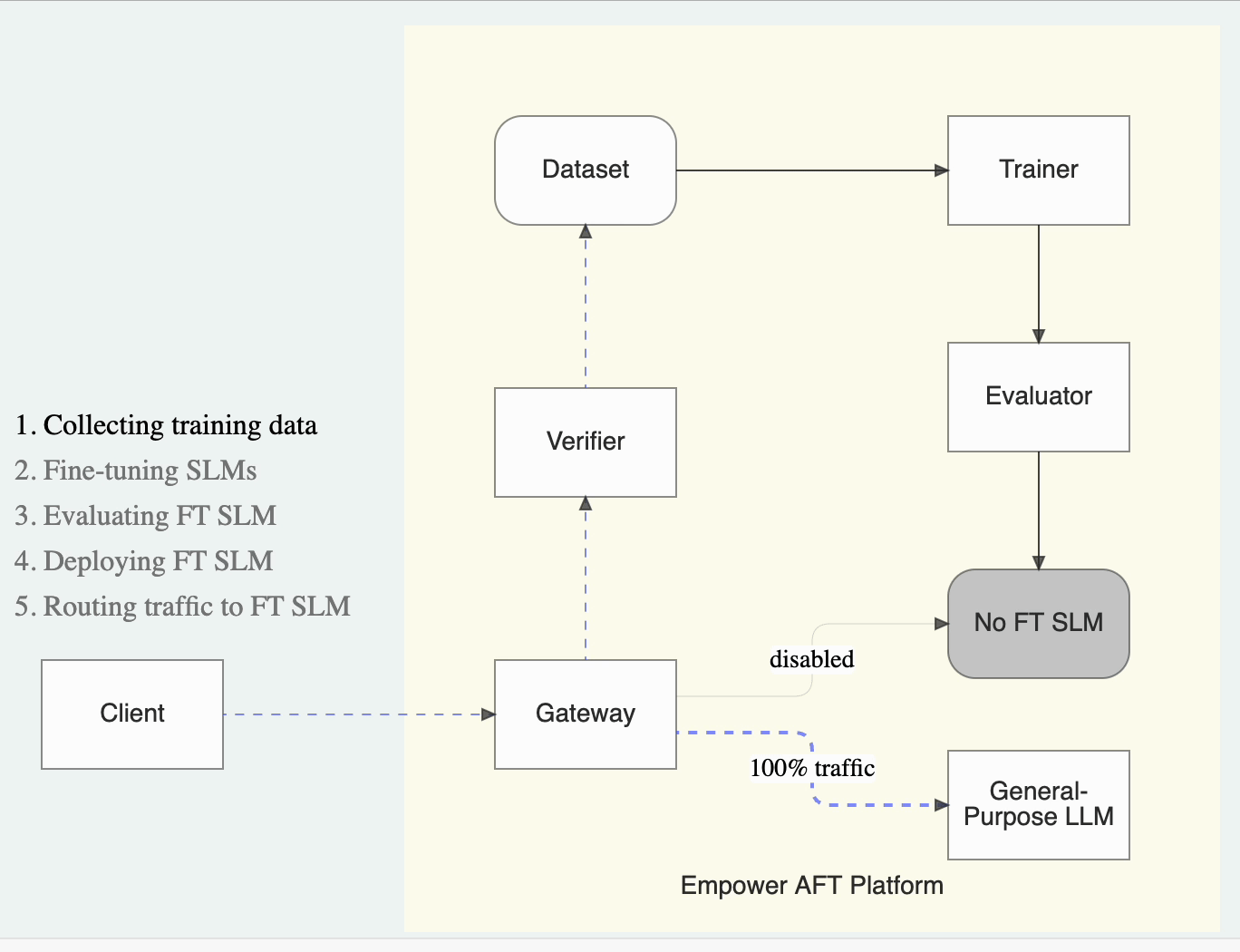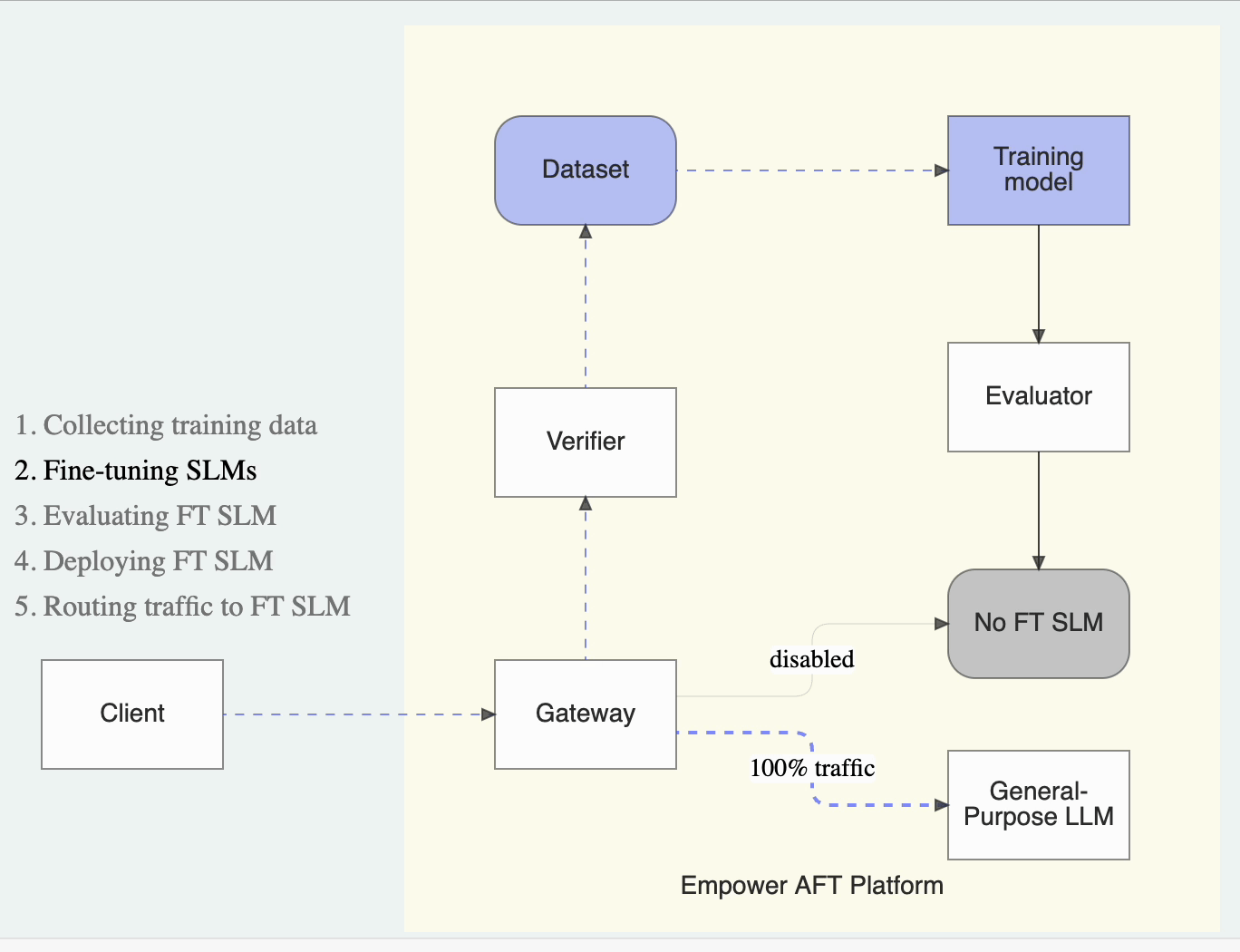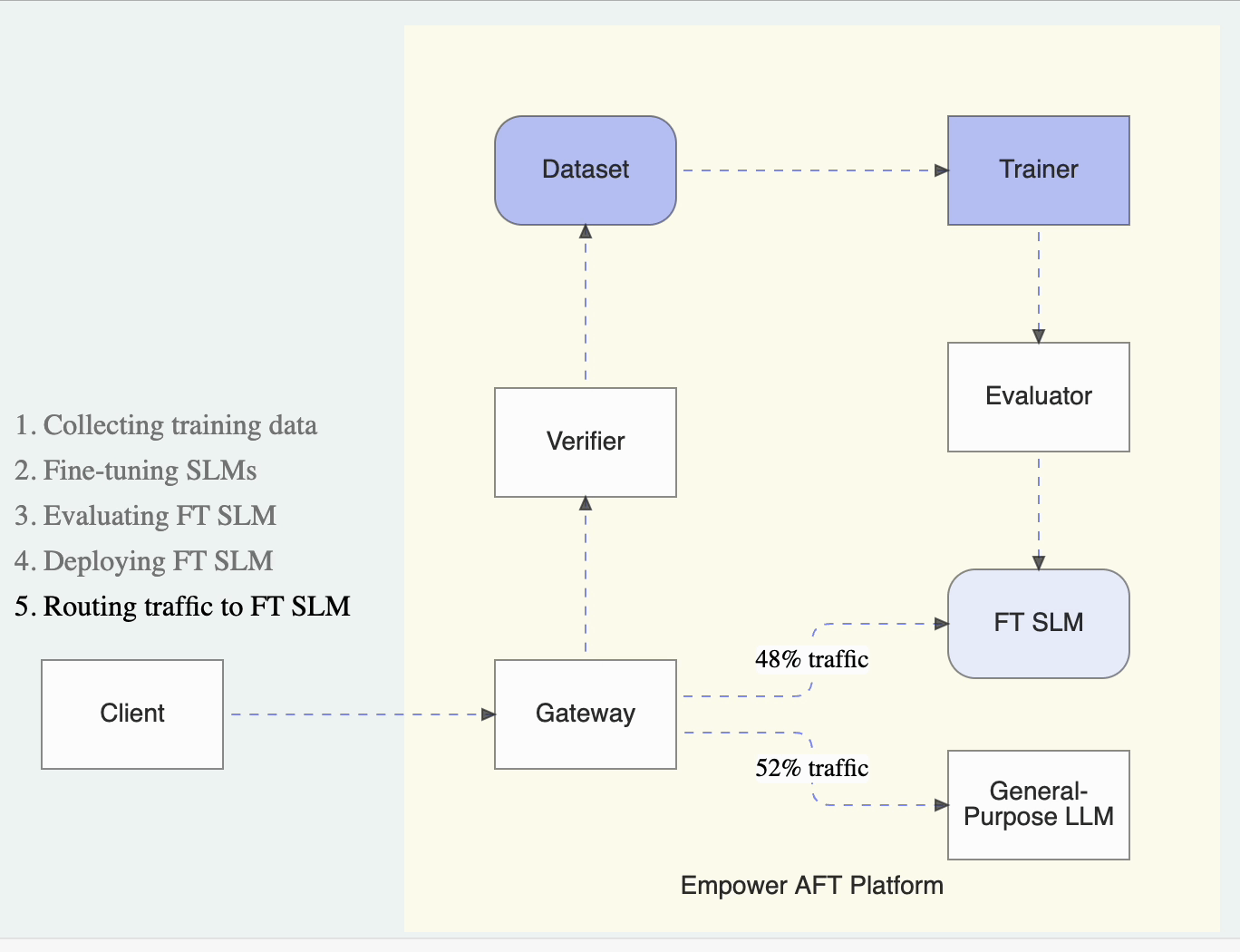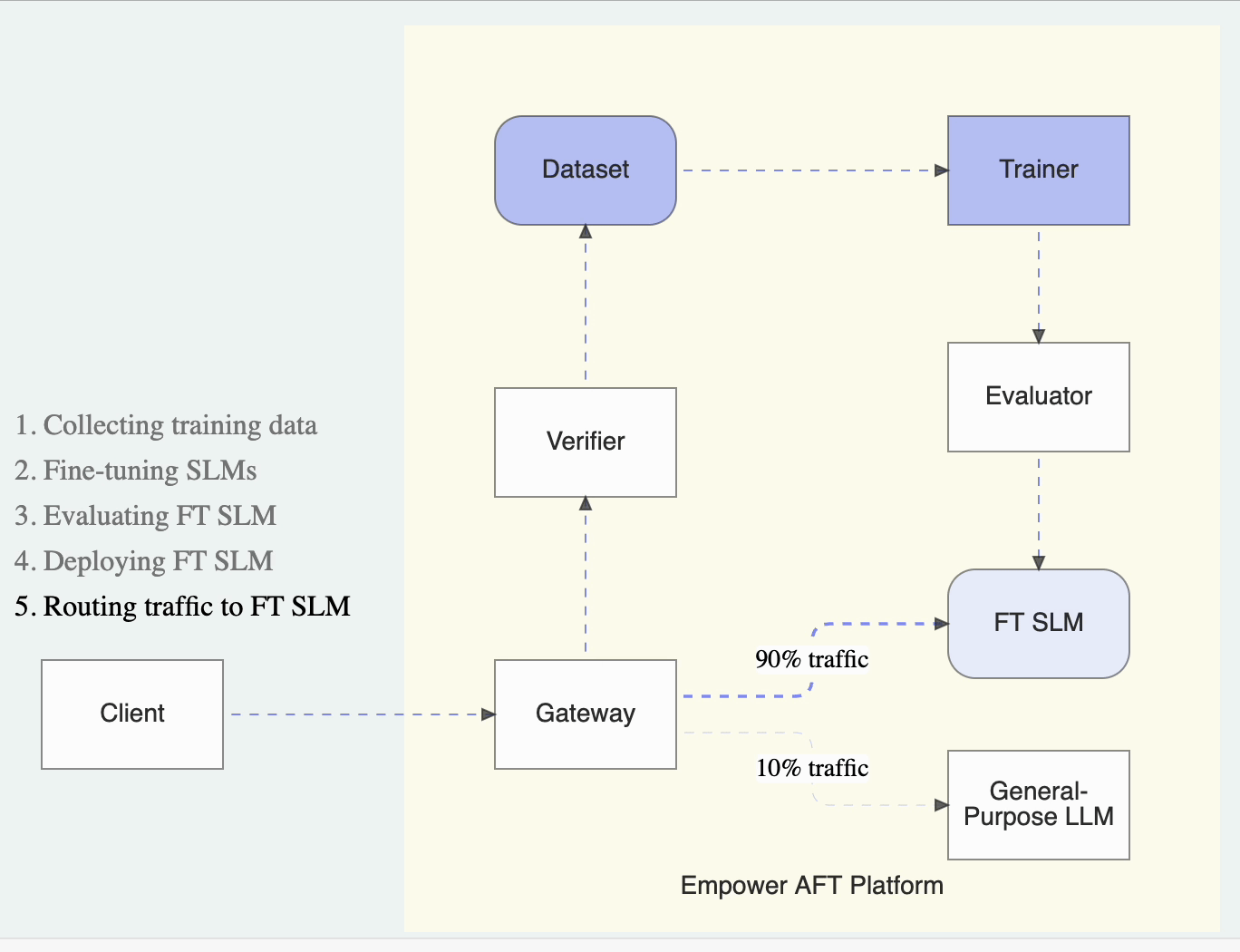
In the Empower AFT platform, tasks serve as the core units for organizing and managing LLM requests. When a new task is created, all traffic is initially directed to the designated general-purpose LLM. As the system gathers data and fine-tunes a specialized model for the task, the platform gradually shifts traffic from the general-purpose LLM to the newly fine-tuned SLM. This automatic transition optimizes performance and reduces costs, ensuring that customers’ applications benefit from the most efficient and effective model over time.
Below, we will explain in detail how the AFT platform works:
Integration
After a task is created, integrating with the Empower AFT platform is as simple as changing 5 lines of code:
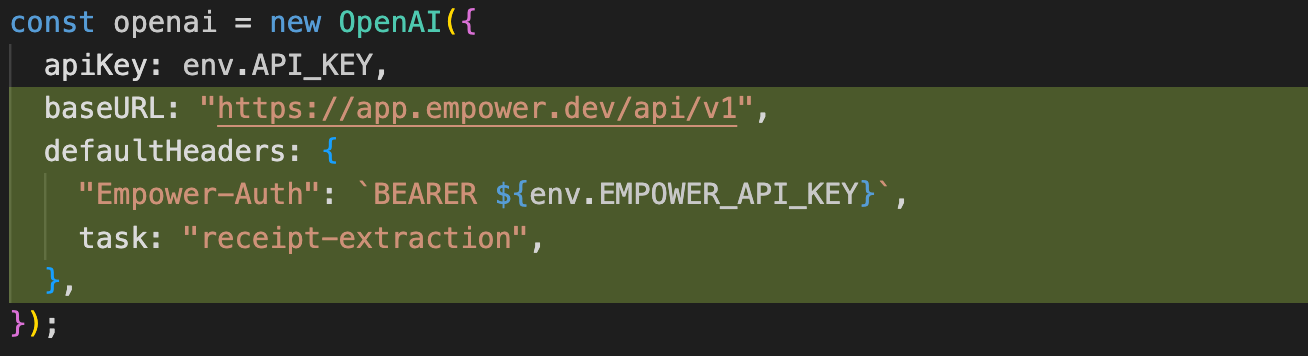
Once the changes are deployed, all LLM requests are routed through the Empower AFT’s gateway. The gateway proxies traffic to the designated general-purpose LLM while simultaneously capturing request and response data. This data is then utilized for fine-tuning SLMs.
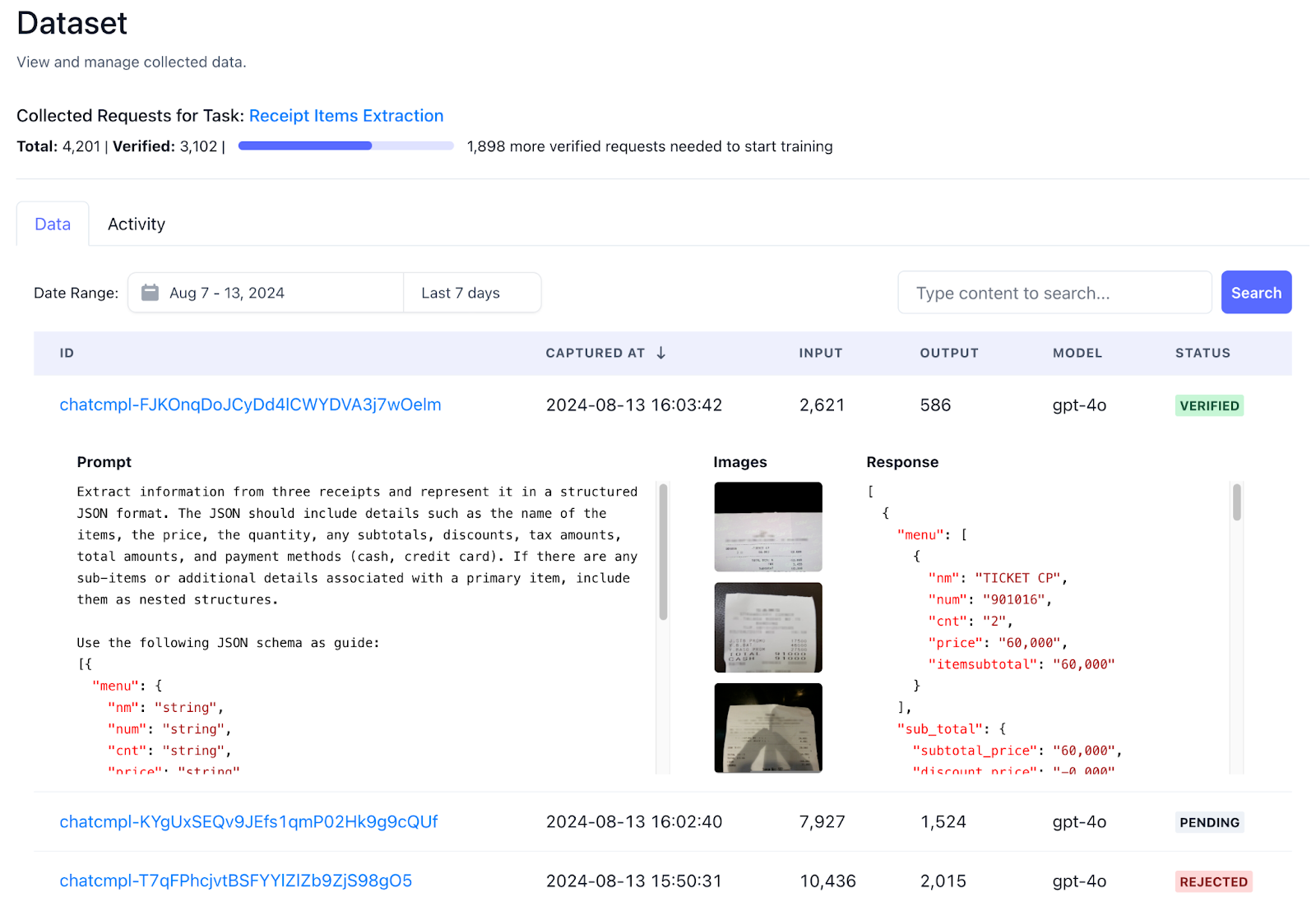
Data Capturing
LLM requests proxied by the gateway are stored in a task-specific dataset and reviewed by the verifier. The verifier ensures the integrity of these requests through the designated mechanism, either an auto-verification LLM call, heuristic rules, or an additional manual verification API request. Once verified, these requests are injected into the training dataset used to fine-tune the task-specific SLM.
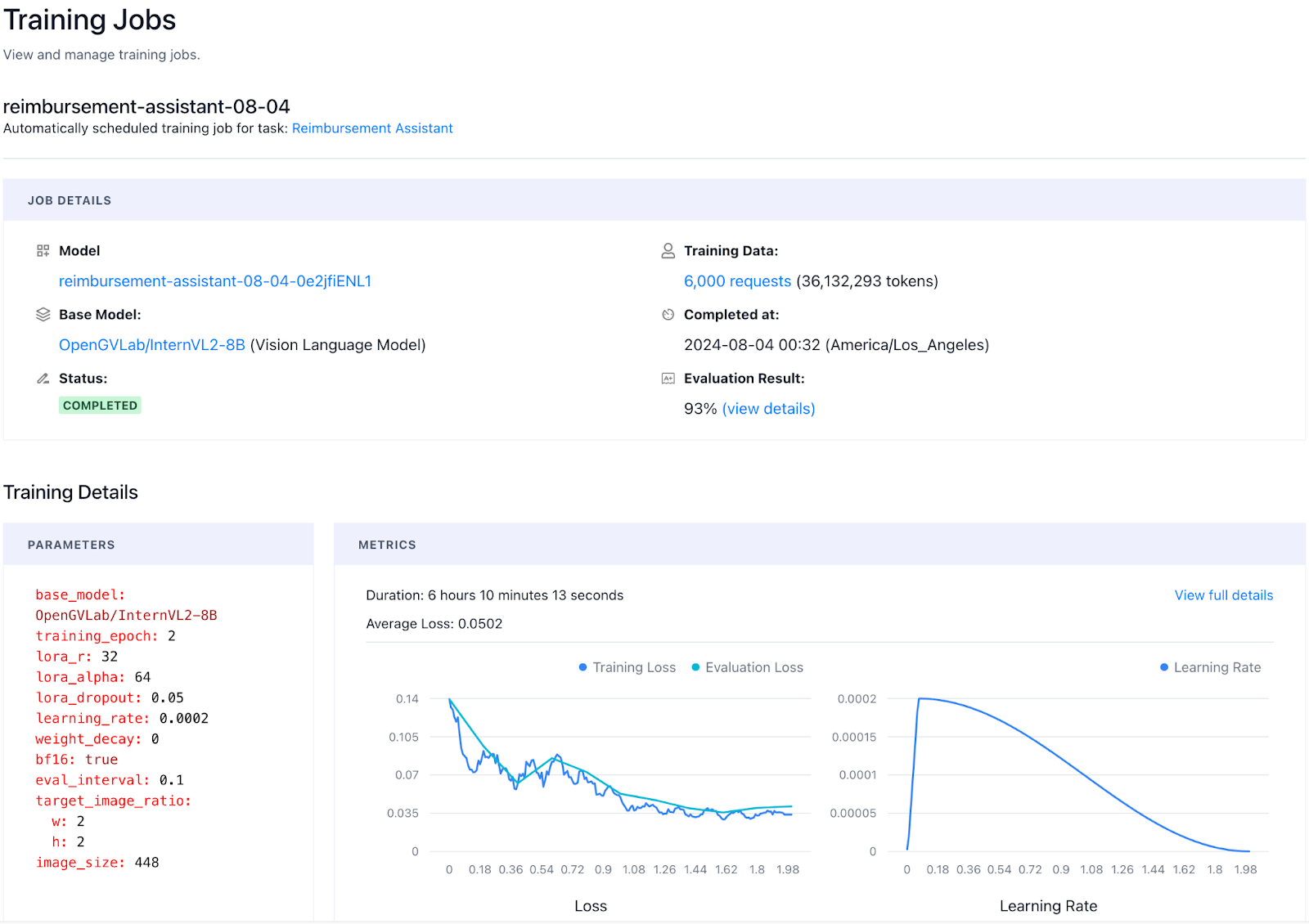
Auto Model Fine-Tuning
AFT automatically initiates the fine-tuning job once sufficient data is collected for a given task. During this process, the AFT platform determines the optimal parameters for training the model, including base model selection, hyperparameters, and dataset sampling strategies, then iterates and evaluates the model to select the best candidate.
Traffic Splitting and Model Refreshing
Once a fine-tuned SLM is ready, subsequent LLM requests routed through the Empower gateway will be automatically split between the fine-tuned SLM and general-purpose LLMs. By default, AFT directs 90% of incoming requests to the fine-tuned SLM, while the remaining 10% are sent to the designated general-purpose LLM. This 10% split ensures that the model remains accurate and current by continuously evaluating the SLM’s performance and facilitating automatic updates.
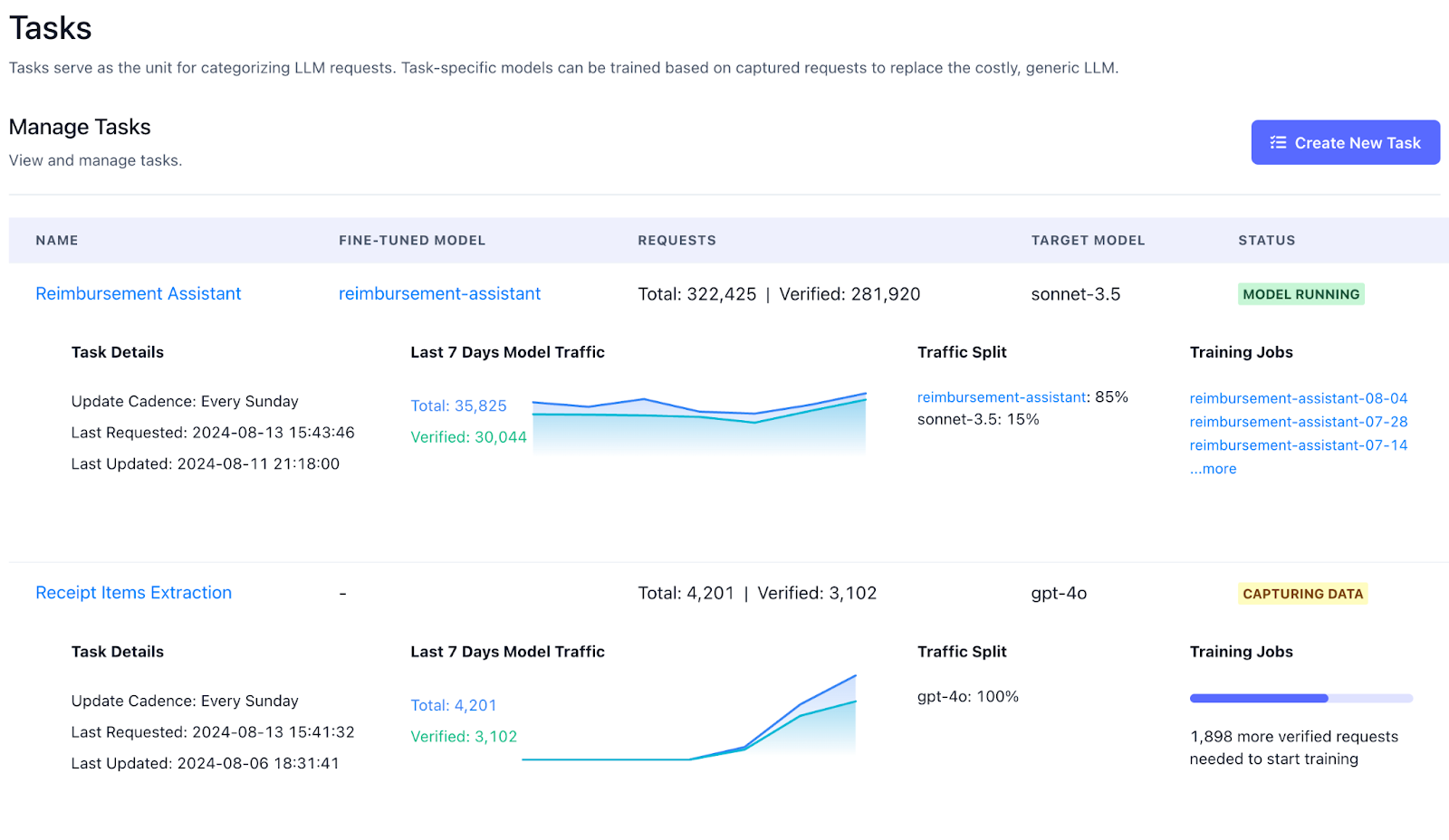
As LLM requests evolve, AFT keeps the fine-tuned models up-to-date on a designated schedule. With the auto model refreshing feature, users customize the update cadence, enabling the fine-tuned SLMs to adapt continually to new data and maintain consistent performance.
Pricing
We offer a straightforward pricing model: 20% of the LLMs bill saving, inclusive of the model training, data storage, and inference usage.
Get Access
Ready to explore how the Empower AFT platform can help reduce your LLM costs? We are currently conducting a private beta program. We are looking for customers who:
- Utilize mainstream general-purpose LLMs, such as GPT-4o, Claude Sonnet/Claude Opus, Gemini Pro, etc.
- Have AI-powered products in production that consume at least 200 million LLM tokens per month.
Sign up for the beta program by submitting this form, scheduling a meeting, or emailing us to discuss how we can support your use case!
