How to maintain engineering velocity as you scale
by Marcelo Cortes10/25/2022

Engineering is typically the function that grows fastest at a scaling startup. It requires a lot of attention to make sure the pace of execution does not slow and cultural issues do not emerge as you scale.
We’ve learned a lot about pace of execution in the past five years at Faire. When we launched in 2017, we were a team of five engineers. From the beginning, we built a simple but solid foundation that allowed us to maintain both velocity and quality. When we found product-market fit later that year and started bringing on lots of new customers, instead of spending engineering resources on re-architecturing our platform to scale, we were able to double down on product engineering to accelerate the growth. In this post, we discuss the guiding principles that allowed us to maintain our engineering velocity as we scaled.
Four guiding principles to maintaining velocity
Faire’s engineering team grew from five to over 100 engineers in three years. Throughout this growth, we were able to sustain our pace of engineering execution by adhering to four important elements:
- Hiring the best engineers
- Building solid long-term foundations from day one
- Tracking metrics to guide decision-making
- Keeping teams small and independent
1. Hire the best engineers
You want to hire the best early team that you can, as they’re going to be the people helping you scale and maintain velocity. And good people follow good people, helping you grow your team down the road.
This sounds obvious, but it’s tempting to get people in seats fast because you have a truckload of priorities and you’re often the only one doing engineering recruiting in those early years. What makes this even harder is you often have to play the long game to get the best engineers signed on. Your job is to build a case for why your company is the opportunity for them.
We had a few amazing engineers in mind we wanted to hire early on. I spent over a year doing coffee meetings with some of them. I used these meetings to get advice, but more importantly I was always giving them updates on our progress, vision, fundraising, and product releases. That created FOMO which eventually got them so excited about what was happening at Faire that they signed up for the ride.
While recruiting, I looked for key competencies that I thought were vital for our engineering team to be successful as we scaled. These were:
a. Experts at our core technology
In early stages, you need to move extremely fast and you cannot afford to make mistakes. We wanted the best engineers who had previously built the components we needed so they knew where mistakes could happen, what to avoid, what to focus on, and more. For example, we built a complex payments infrastructure in a couple of weeks. That included integrating with multiple payment processors in order to charge debit/credit cards, process partial refunds, async retries, voiding canceled transactions, and linking bank accounts for ACH payouts. We had built similar infrastructure for the Cash App at Square and that experience allowed us to move extremely quickly while avoiding pitfalls.
b. Focused on delivering value to customers
Faire’s mission is to empower entrepreneurs to chase their dreams. When hiring engineers, we looked for people who were amazing technically but also understood our business, were customer focused, were passionate about entrepreneurship—and understood how they needed to work. That is, they understood how to use technology to add value to customers and product, quickly and with quality. To test for this, I would ask questions like: “Give me examples of how you or your team impacted the business.” Their answers would show how well they understood their current company’s business and how engineering can impact customers and change a company’s top-line numbers.
I also learned a lot when I let them ask questions about Faire. I love when engineering candidates ask questions about how our business works, how we make money, what our market size is, etc. If they don't ask these kinds of questions, I ask them things like: “Do you understand how Faire works?” “Why is Faire good for retailers?” “How would you sell Faire to a brand?” After asking questions like these a few times, you’ll see patterns and be able to quickly identify engineers who are business-minded and customer-focused.
Another benefit of hiring customer-focused engineers is that it’s much easier to shut down projects, start new ones, and move people around, because everyone is focused on delivering value for the customer and not wedded to the products they helped build. During COVID, our customers saw enormous change, with in-person trade shows getting canceled and lockdowns impacting in-person foot traffic. We had to adapt quickly, which required us to stop certain initiatives and move our product and engineering teams to launch new ones, such as our own version of online trade shows.
c. Grit
When we first started, we couldn’t afford to build the most beautiful piece of engineering work. We had to be fast and agile. This is critical when you are pre-product-market fit. Our CEO Max and a few early employees would go to trade shows to present our product to customers, understand their needs, and learn what resonated with them. Max would call us with new ideas several times a day. It was paramount that our engineers were gritty and able to quickly make changes to the product. Over the three or four days of a trade show, our team deployed changes nonstop to the platform. We experimented with offerings like:
- Free shipping on first orders
- Buy now, pay later
- Buy from a brand and get $100 off when you re-order from the same brand
- Free returns
By trying different value propositions in a short time, our engineering team helped us figure out what was most valuable to our customers. That was how we found strong product-market fit within six months of starting the company.

Our trade show storefront back when we were called Indigo Fair.
2. Build a solid long-term foundation from day one
The number one impediment to engineering velocity at scale is a lack of solid, consistent foundation. A simple but solid foundation will allow your team to keep building on top of it instead of having to throw away or re-architecture your base when hypergrowth starts.
To create a solid long-term foundation, you first need to get clear on what practices you believe are important for your engineering team to scale. For example, I remember speaking with senior engineers at other startups who were surprised we were writing tests and doing code reviews and that we had a code style guide from the very early days. But we couldn’t have operated well without these processes. When we started to grow fast and add lots of engineers, we were able to keep over 95% of the team focused on building features and adding value to our customers, increasing our growth.
Once you know what long-term foundations you want to build, you need to write it down. We were intentional about this from day one and documented it in our engineering handbook. Today, every engineer is onboarded using this handbook.
The four foundational elements we decided on were:
a. Being data-driven
The most important thing is to build your data muscle early. We started doing this at 10 customers. At the time, the data wasn’t particularly useful; the more important thing was to start to collect it. At some point, you’ll need data to drive product decision-making. The longer you wait, the harder it is to embed into your team.
Here’s what I recommend you start doing as early as possible:
- Set up data pipelines that feed into a data warehouse.
- Start collecting data on how people are using your product. As you add features and iterate, record how those changes are impacting user interactions. All of this should go into a data warehouse that is updated within minutes and made available to your team. As your product gets increasingly complex, it will become more and more important to use data to validate your intuition.
- We use Redshift to store data. As user events are happening, our relational database (MySQL) replicates them in Redshift. Within minutes, the data is available for queries and reports.
- Train your team to use experimentation frameworks.
- Make it part of the product development process. The goal is to transform your intuition into a statistically testable statement. A good place to start is to establish principles and high-level steps for your team to follow when they run experiments. We’ve set principles around when to run experiments vs. when not to, that running rigorous experiments should be the default (and when it isn’t), and when to stop an experiment earlier than expected. We also have teams log experiments in a Notion dashboard.
- The initial focus should be on what impact you think a feature will have and how to measure that change. As you’re scoping a feature, ask questions like: How are we going to validate that this feature is achieving intended goals? What events/data do we need to collect to support that? What reports are we going to build? Over time, these core principles will expand.
- The entire team should be thinking about this, not just the engineers or data team. We reinforced the importance of data fluency by pushing employees to learn SQL, so that they could run their own queries and experience the data firsthand.
- It’ll take you multiple reps to get this right. We still miss steps and fail to collect the right data. The sooner you get your team doing this, the easier it will be to teach it to new people and become better at it as an organization.
b. Our choice of programming language and database
When choosing a language and database, pick something you know best that is also scalable long-term. If you choose a language you don’t know well because it seems easier or faster to get started, you won’t foresee pitfalls and you’ll have to learn as you go. This is expensive and time-consuming. We started with Java as our backend programming language and MySQL as our relational database. In the early days, we were building two to three features per week and it took us a couple of weeks to build the framework we needed around MySQL. This was a big tradeoff that paid dividends later on.
c. Writing tests from day one
Many startups think they can move faster by not writing tests; it’s the opposite. Tests help you avoid bugs and prevent legacy code at scale. They aren’t just validating the code you are writing now. They should be used to enforce, validate, and document requirements. Good tests protect your code from future changes as your codebase grows and features are added or changed. They also catch problems early and help avoid production bugs, saving you time and money. Code without tests becomes legacy very fast. Within months after untested code is written, no one will remember the exact requirements, edge cases, constraints, etc. If you don’t have tests to enforce these things, new engineers will be afraid of changing the code in case they break something or change an expected behavior.
There are two reasons why tests break when a developer is making code changes:
- Requirements change. In this case, we expect tests to break and they should be updated to validate and enforce the new requirements.
- Behavior changes unexpectedly. For example, a bug was introduced and the test alerted us early in the development process.
Every language has tools to measure and keep track of test coverage. I highly recommend introducing them early to track how much of your code is protected by tests. You don’t need to have 100% code coverage, but you should make sure that critical paths, important logic, edge cases, etc. are well tested. Here are tips for writing good tests.
d. Doing code reviews
We started doing code reviews when we hired our first engineer. Having another engineer review your code changes helps ensure quality, prevents mistakes, and shares good patterns. In other words, it’s a great learning tool for new and experienced engineers. Through code reviews, you are teaching your engineers patterns: what to avoid, why to do something, the features of languages you should and shouldn’t use.
Along with this, you should have a coding style guide. Coding guides help enforce consistency and quality on your engineering team. It doesn’t have to be complex. We use a tool that formats our code so our style guide is automatically enforced before a change can be merged. This leads to higher code quality, especially when teams are collaborating and other people are reviewing code.
We switched from Java to Kotlin in 2019 and we have a comprehensive style guide that includes recommendations and rules for programming in Kotlin. For anything not explicitly specified in our guide, we ask that engineers follow JetBrains’ coding conventions.
These are the code review best practices we share internally:
- #bekind when doing a code review. Use positive phrasing where possible ("there might be a better way" instead of "this is terrible"; "how about we name this X?" instead of "naming this Y is bad"). It's easy to unintentionally come across as critical, especially if you have a remote team.
- Don't block changes from being merged if the issues are minor (e.g., a request for variable name change, indentation fixes). Instead, make the ask verbally. Only block merging if the request contains potentially dangerous changes that could cause issues or if there is an easier/safer way to accomplish the same.
- When doing a code review, ensure that the code adheres to your style guide. When giving feedback, refer to the relevant sections in the style guide.
- If the code review is large, consider checking out the branch locally and inspecting the changes in IntelliJ (Git tab on the bottom). It’s easier to have all of the navigation tools at hand.
3. Track engineering metrics to drive decision-making
Tracking metrics is imperative to maintaining engineering velocity. Without clear metrics, Faire would be in the dark about how our team is performing and where we should focus our efforts. We would have to rely on intuition and assumptions to guide what we should be prioritizing.
Examples of metrics we started tracking early (at around 20 engineers) included:
- Uptime. One of the first metrics we tracked was uptime. We started measuring this because we were receiving anecdotal reports of site stability issues. Once we started tracking it, we confirmed the anecdotal evidence and dedicated a few engineers to resolve the issue.
- CI wait time. Another metric that was really important was CI wait time (i.e., time for the build system to build/test pull requests). We were receiving anecdotal reports of long CI wait times for developers, confirmed it with data, and fixed the issue.
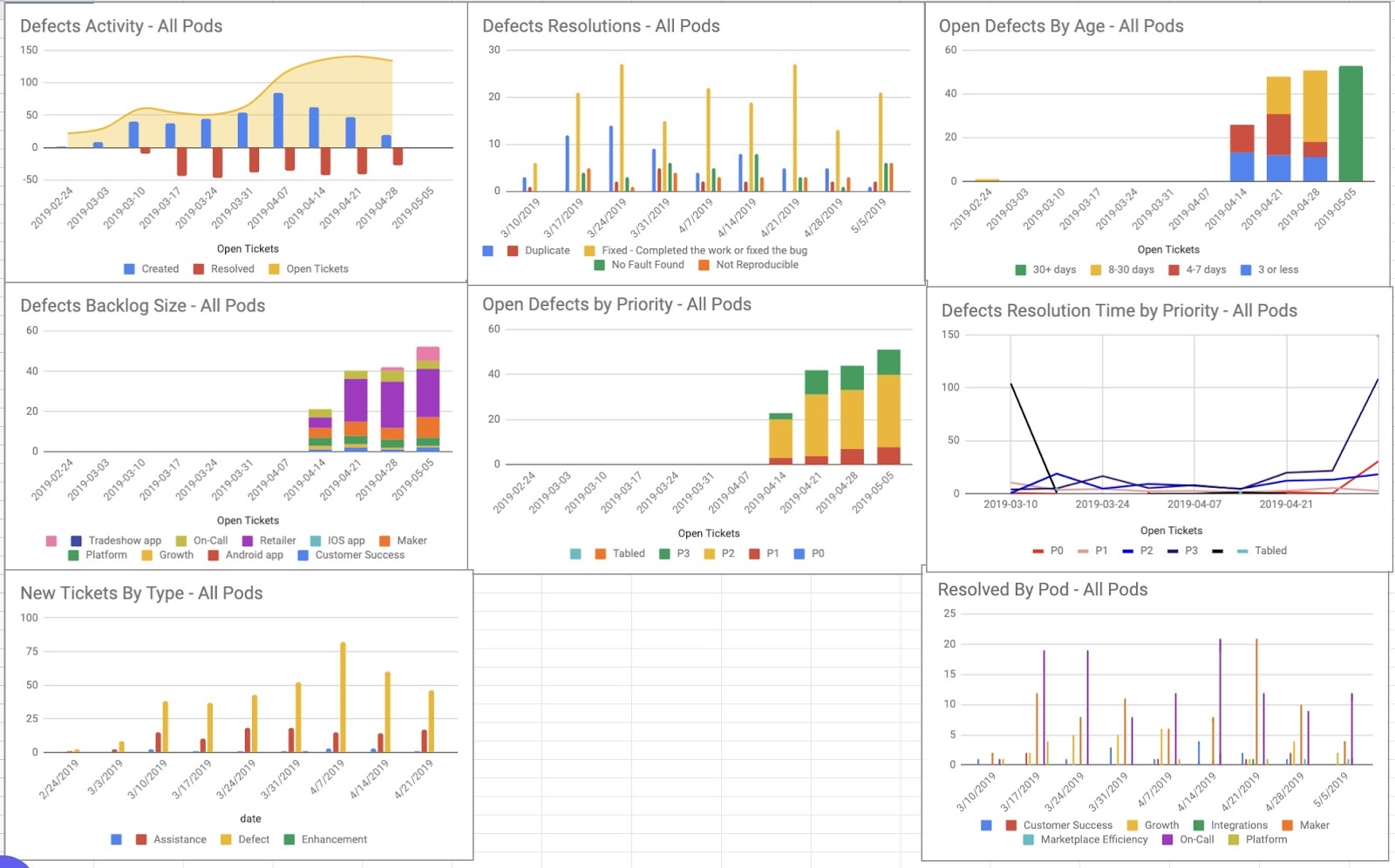
This is a dashboard we created in the early days of Faire to track important engineering metrics. It was updated manually by collecting data from different sources. Today, we have more comprehensive dashboards that are fully automated.
Once our engineering team grew to 100+, our top-level metrics became more difficult to take action against. When metrics trended beyond concerning thresholds, we didn’t have a clear way to address them. Each team was busy with their own product roadmap, and it didn’t seem worthwhile to spin up new teams to address temporary needs. Additionally, many of the problems were large in scale and would have required a dedicated group of engineers.
We found that the best solution was to build dimensions so that we could view metrics by team. Once we had metrics cut by team, we could set top-down expectations and priorities. We were happy to see that individual teams did a great job of taking ownership of and improving their metrics and, consequently, the company’s top-level metrics.
An example: transaction run duration
Coming out of our virtual trade show, Faire Summer Market, we knew we needed significant investment in our database utilization. During the event, site usage pushed our database capacity to its limits and we realized we wouldn’t be able to handle similar events in the future.
In response, we created a metric of how long transactions were open every time our application interacted with the database. Each transaction was attributed to a specific team. We then had a visualization of the hottest areas of our application along with the teams responsible for those areas. We asked each team to set a goal during our planning process to reduce their database usage by 20% over a three-month period. The aggregate results were staggering. Six months later, before our next event—Faire Winter Market—incoming traffic was 1.6x higher, but we were nowhere close to maxing out our database capacity. Now, each team is responsible for monitoring their database utilization and ensuring it doesn’t trend in the wrong direction.
Managing metrics with KPI scorecards
We’re moving towards a model where each team maintains a set of key performance indicators (KPIs) that get published as a scorecard reflecting how successful the team is at maintaining its product areas and the parts of the tech stack it owns.
We’re starting with a top-level scorecard for the whole engineering team that tracks our highest-level KPIs (e.g., Apdex, database utilization, CI wait time, severe bug escapes, flaky tests). Each team maintains a scorecard with its assigned top-level KPIs as well as domain-specific KPIs. As teams grow and split into sub-teams, the scorecards follow the same path recursively. Engineering leaders managing multiple teams use these scorecards to gauge the relative success of their teams and to better understand where they should be focusing their own time.
Scorecard generation should be as automated and as simple as possible so that it becomes a regular practice. If your process requires a lot of manual effort, you’re likely going to have trouble committing to it on a regular cadence. Many of our metrics start in DataDog; we use their API to extract relevant metrics and push them into Redshift and then visualize them in Mode reports.
As we’ve rolled this process out, we’ve identified criteria for what makes a great engineering KPI:
- Can be measured and has a believable source of truth. If capturing and viewing KPIs is not an easy and repeatable task, it’s bound to stop happening. Invest in the infrastructure to reliably capture KPIs in a format that can be easily queried.
- Clearly ladders up to a top-level business metric. If there isn’t a clear connection to a top-level business metric, you’ll have a hard time convincing stakeholders to take action based on the data. For example, we’ve started tracking pager volume for our critical services: High pager volume contributes to tired and distracted engineers which leads to less code output, which leads to fewer features delivered, which ultimately means less customer value.
- Is independent of other KPIs. When viewing and sharing KPIs, give appropriate relative weight to each one depending on your priorities. If you’re showing two highly correlated KPIs (e.g., cycle time and PR throughput), then you’re not leaving room for something that’s less correlated (e.g., uptime). You might want to capture some correlated KPIs so that you can quickly diagnose a worrying trend, but you should present non-duplicative KPIs when crafting the overall scorecard that you share with stakeholders.
- Is normalized in a meaningful way. Looking at absolute numbers can be misleading in a high-growth environment, which makes it hard to compare performance across teams. For example, we initially tracked growth of overall infrastructure cost. The numbers more than doubled every year, which was concerning. When we later normalized this KPI by the amount of revenue a product was producing, we observed the KPI was flat over time. Now we have a clear KPI of “amount spent on infrastructure to generate $1 in revenue.” This resulted in us being comfortable with our rate of spend, whereas previously we were considering staffing a team to address growing infrastructure costs.
We plan to keep investing in this area as we grow. KPIs allow us to work and build with confidence, knowing that we’re focusing on the right problems to continue serving our customers.
4. Keep teams small and independent
When we were a company of 25 employees, we had a single engineering team. Eventually, we split into two teams in order to prioritize multiple areas simultaneously and ship faster. When you split into multiple teams, things can break because people lose context. To navigate this, we developed a pod structure to ensure that every team was able to operate independently but with all the context and resources they needed.
When you first create a pod structure, here are some rules of thumb:
- Pods should operate like small startups. Give them a mission, goals, and the resources they need. It’s up to them to figure out the strategy to achieve those goals. Pods at Faire typically do an in-person offsite to brainstorm ideas and come up with a prioritized roadmap and expected business results, which they then present for feedback and approval.
- Each pod should have no more than 8 to 10 employees. For us, pods generally include 5 to 7 engineers (including an engineering manager), a product manager, a designer, and a data scientist.
- Each pod should have a clear leader. We have an engineering manager and a product manager co-lead each pod. We designed it this way to give engineering a voice and more ownership in the planning process.
- Expect people to be members of multiple pods. While this isn’t ideal, there isn’t any other way to do it early on. Resources are constrained, and you need a combination of seasoned employees and new hires on each pod (otherwise they’ll lack context). Pick one or two people who have lots of context to seed the pod, then add new members. When we first did this, pods shared backend engineers, designers, and data analysts, and had their own product manager and frontend engineer.
- If you only have one product, assign a pod to each well-defined part of the product. If there’s not an obvious way to split up your product surface area, try to break it out into large features and assign a pod to each.
- Keep reporting lines and performance management within functional teams. This makes it easier to maintain:
(1) Standardized tooling/processes across the engineering team and balanced leadership between functions
(2) Standardized career frameworks and performance calibration. We give our managers guidance and tools to make sure this is happening. For example, I have a spreadsheet for every manager that I expect them to update on a monthly basis with a scorecard and brief summary of their direct reports’ performance.
How we stay on top of resource allocation: Census and Horsepower
Our engineering priorities change often. We need to be able to move engineers around and create, merge, split, or sunset pods. In order to keep track of who is on which team—taking into account where that person is located, their skill set, tenure at the company, and more—we built a tool called Census.
Census is a real-time visualization of our team’s structure. It automatically updates with data from our ATS and HR system. The visual aspect is crucial and makes it easier for leadership to make decisions around resource allocation and pod changes as priorities shift. Alongside Census, we also built an algorithm to evaluate the “horsepower” of a pod. If horsepower is showing up as yellow or red, that pod either needs more senior engineers, has a disproportionate number of new employees, or both.
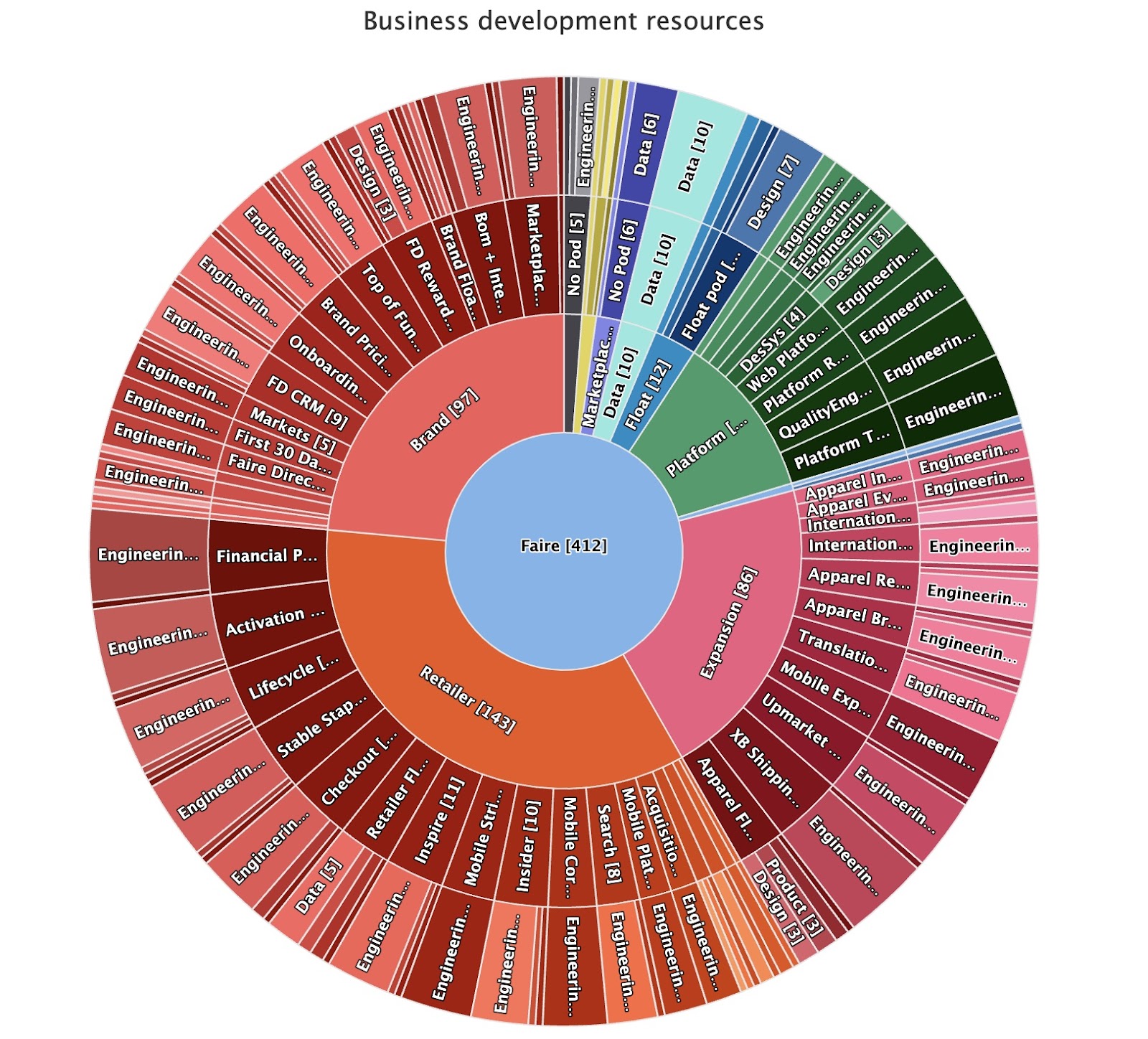
Census.
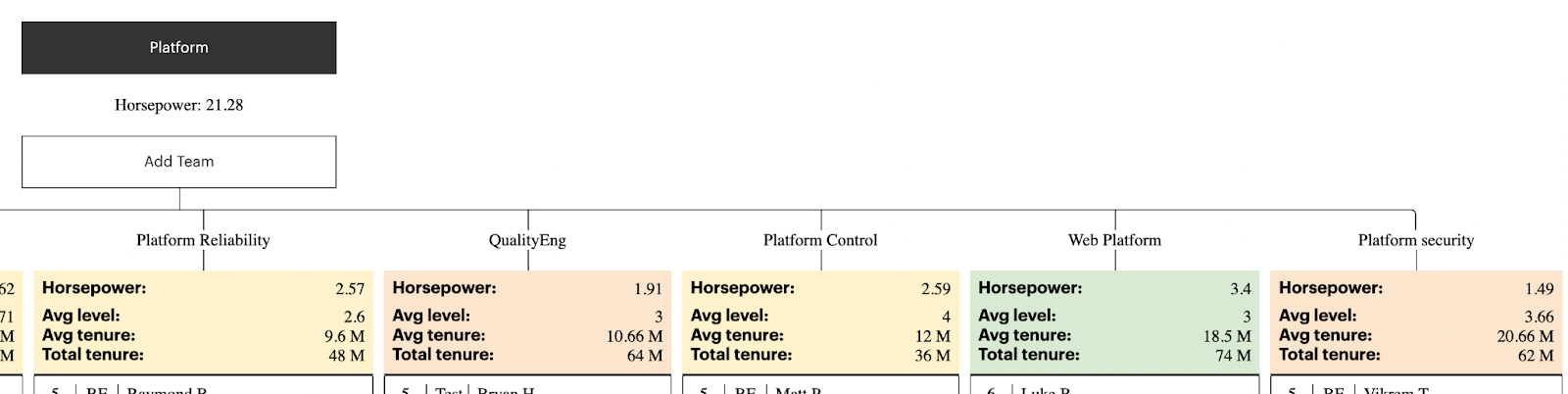
Pods are colored either green, yellow, or red depending on their horsepower.
One of the most common questions that founders have is how to balance speed with everything else: product quality, architecture debt, team culture. Too often, startups stall out and sacrifice their early momentum in order to correct technical debt. In building Faire, we set out to both establish a unified foundation and continue shipping fast. These four guiding principles are how we did it, and I hope they help others do the same.

Other Posts
Author

Marcelo Cortes
Marcelo Cortes is a co-founder and the CTO of Faire, an online wholesale marketplace connecting mostly small brands to independent, local retailers.