
Circlemind is an open-source RAG using knowledge graphs and PageRank.



TL;DR — Circlemind is an open-source RAG that uses knowledge graphs and PageRank for more accurate retrieval. Our RAG is up to 3x more accurate than vector databases. Don’t let poor RAG sabotage your AI application — check out our open-source repository or book a demo and experience the difference accurate retrieval makes.
The Problem
Building a good RAG pipeline these days takes a lot of manual optimizations. Most engineers intuitively start from naive RAG: throw everything in a vector database and hope that semantic search is powerful enough. This can work for use cases where accuracy isn’t too important and hallucinations are tolerable, but it doesn’t work for more difficult queries that involve multi-hop reasoning or more advanced domain understanding. Also, it’s impossible to debug it.
To address these limitations, many engineers find themselves adding extra layers like agent-based preprocessing, custom embeddings, reranking mechanisms, and hybrid search strategies. Much like the early days of machine learning when we manually crafted feature vectors to squeeze out marginal gains, building an effective RAG system often becomes an exercise in crafting engineering “hacks.”
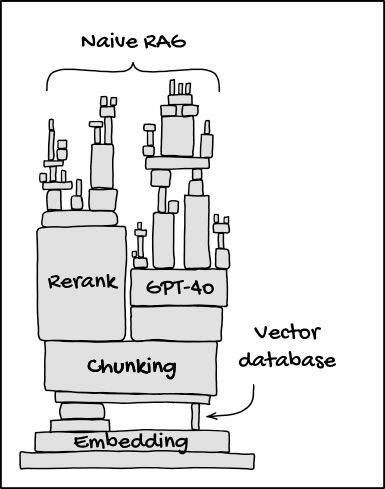
The Solution
Earlier this year, Microsoft seeded the idea of using Knowledge Graphs for RAG and published GraphRAG - i.e. RAG with Knowledge Graphs. We believe that there is a lot of potential in this idea, but existing implementations are naive in the way they create and explore the graph. That’s why we developed Fast GraphRAG with a new algorithmic approach using good old PageRank.
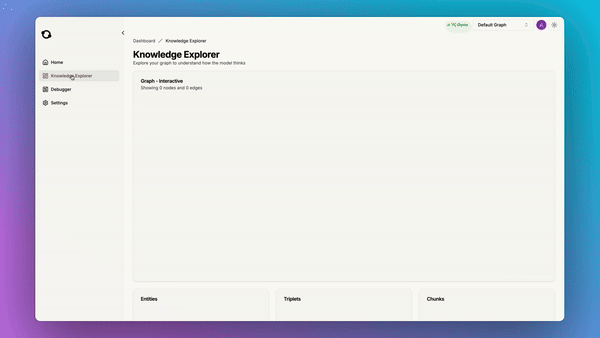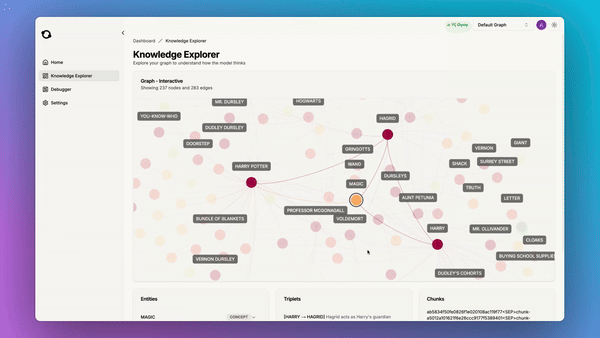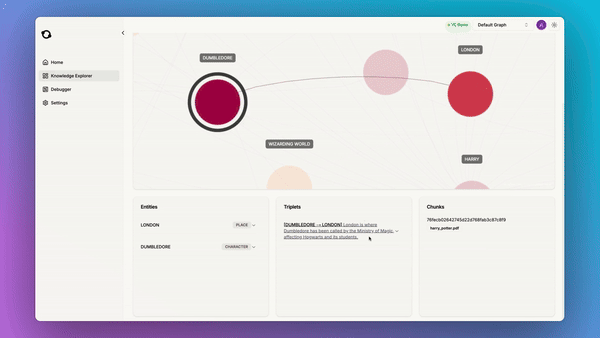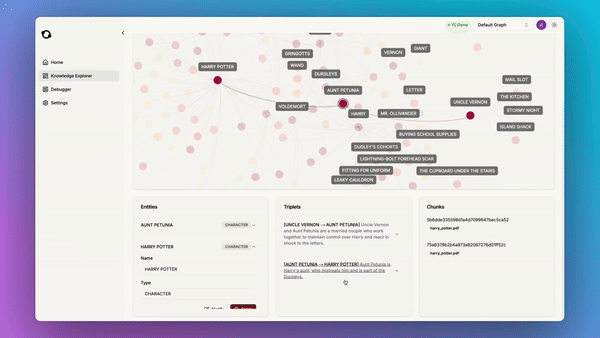
Knowledge graphs store entities and their relationships, and can help structure data in a way that enables more accurate and context-aware information retrieval. 12 years ago Google announced the knowledge graph we all know about. It was a pioneering move. Now we have LLMs, meaning that people can finally do RAG on their own data with tools that can be as powerful as Google’s original idea.
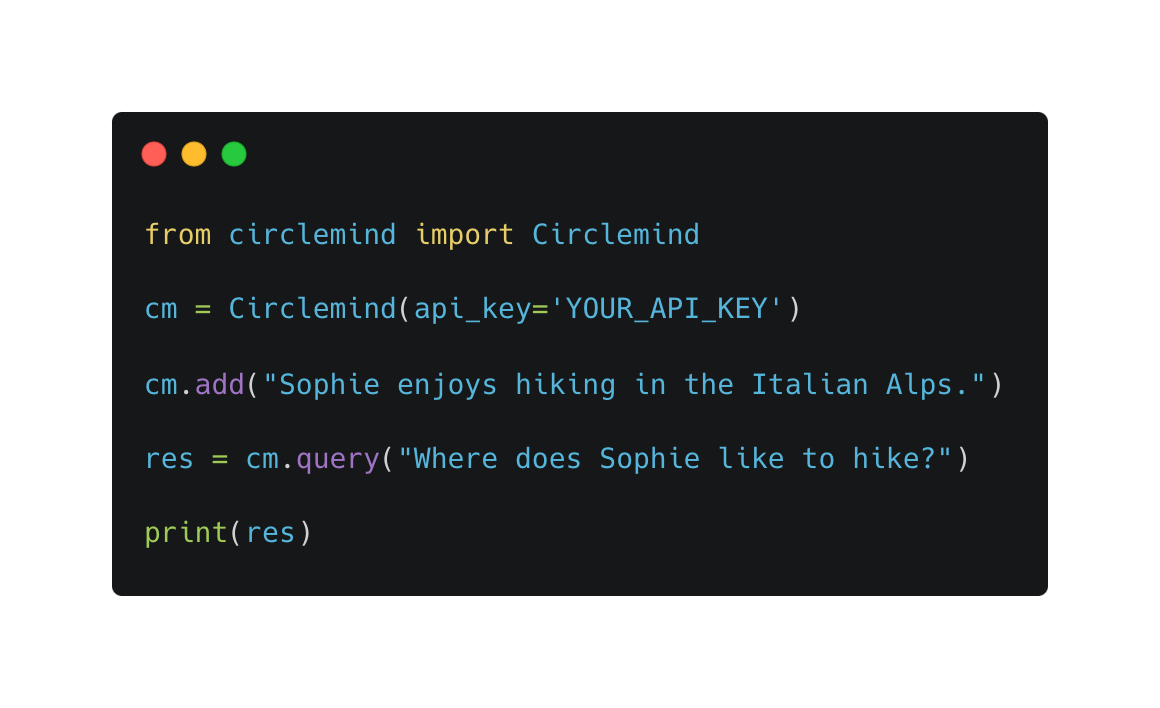
As we understand that running agents and all the integrations necessary for Fast GraphRAG isn’t trivial, we decided to offer a managed service that is dead simple to use. You can try it for free right now on our platform. We make it as simple as using any other database:
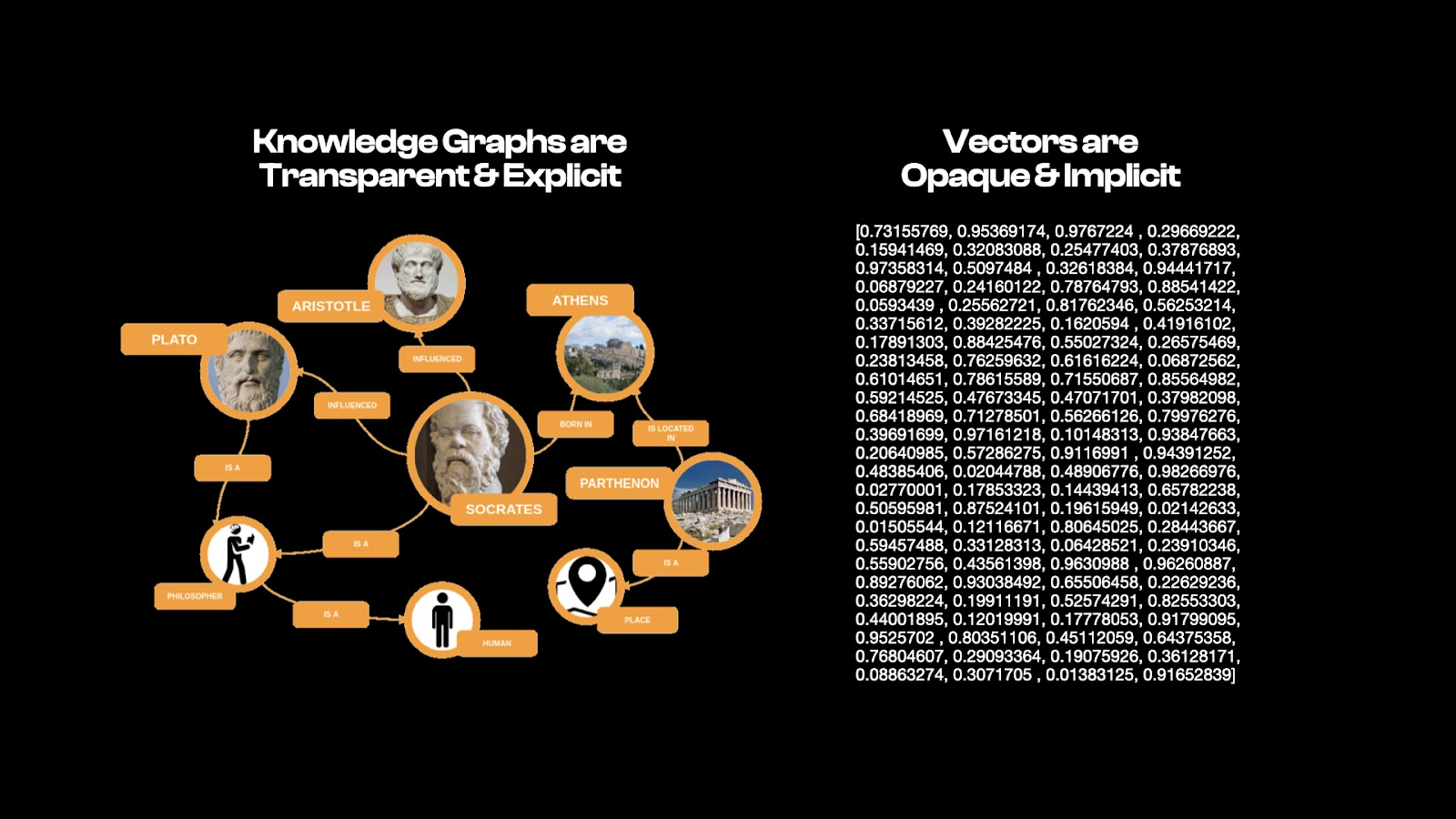
Another great benefit of using graphs is that they are understandable and debuggable:
So we added a built-in debugger tool which allows you to find and fix issues in your knowledge graph:
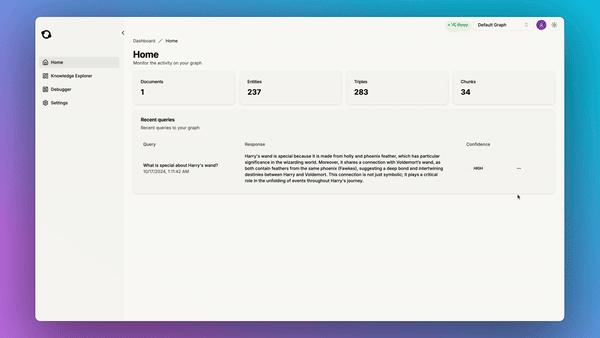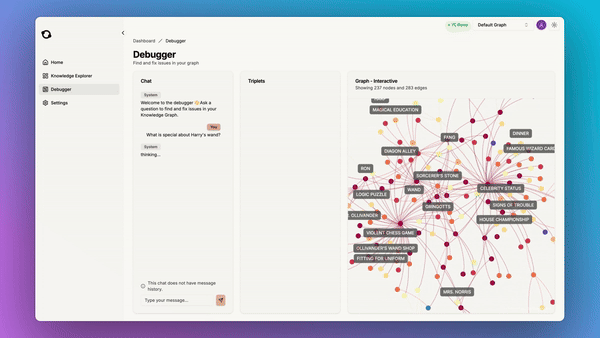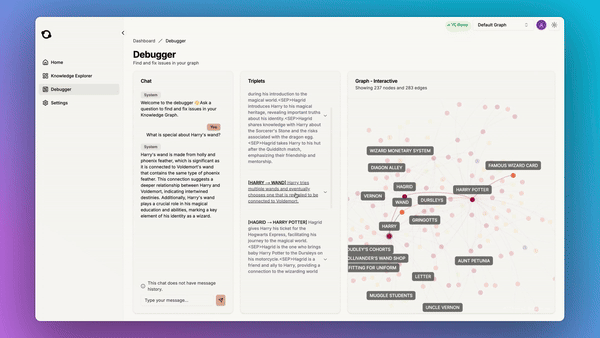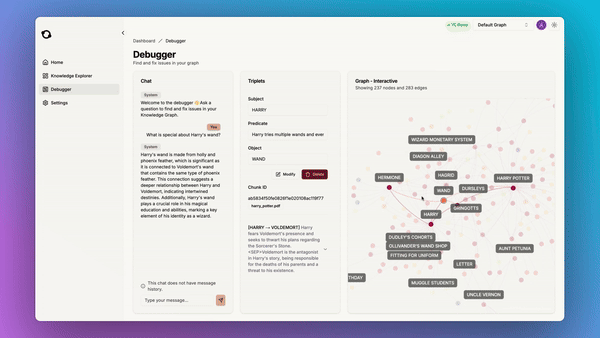
This is the kind of infrastructure that your AI application needs to handle large-scale real-world data. Our goal is to give you this infrastructure so that you can focus on what’s important: building great apps for your users without having to care about manually engineering a retrieval pipeline. In the managed service, we also have a suite of UI tools for you to explore and debug your knowledge graph.
We have a free hosted solution with up to 100 monthly requests. When you’re ready to grow, we have paid plans that scale with you. And of course you can self host our open-source engine.
Give us a spin today at https://circlemind.co and see our code at https://github.com/circlemind-ai/fast-graphrag
Feel free to contact us at founders@circlemind.co

The team
Circlemind is a team of AI researchers and engineers. We are Antonio, Luca, and Yuhang.
Antonio holds a Master’s degree in Computing from Imperial College London. He spent three years as a Software Engineer at AWS, working on real-time streaming technology.
Luca holds a Master's degree in Computer Science from the University of Oxford, where he researched alternative biologically-inspired methods to build neural networks for his PhD studies.
Yuhang holds a PhD in AI from the University of Oxford, first-authored a Nature Neuroscience paper, and cofounded Fractile raising $15M in two years and exiting.